

面向MES的数据采集与整合
2023-05-04 来源:新工业网
随着国内制造业快速发展,于2015年发布的“中国制造2025”这一制造强国战略,各大企业在加速推进自动化、信息化、智能化进程,其中数据采集与整合是各系统必须要解决的重要一环,特别是面向生产现场的制造执行系统MES,需要采集大量设备实时数据、加工、分析并反向控制现场生产及品控设备,而这些数据又普遍独立存储于不同的数据源中,形成一个个“信息孤岛”。
为此本文针对制造业工厂数据采集的需要,设计了面向传统制造企业的数据采集软件架构,解决结构化、非结构化、不同数据库、各种设备端的实时采集、过滤、整合及生产线相关测量,能源等状态反向控制的方案。
1 文本数据采集
生产制造业工控设备,普遍存在单机系统以非数据库方式存储检测,或运行数据。比如,轮胎企业均动检测结果、断面扫描数据、软件运行日志会以文本文件方式进行存储。
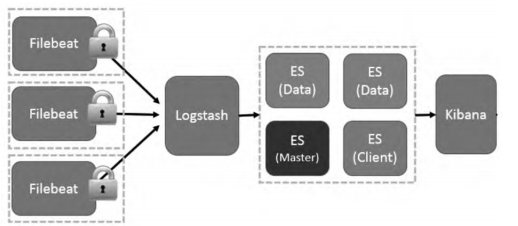
图 1 ELK 架构
在文本(日志)采集方面,开源框架ELK是一套优秀的日志数据解决方案,广泛用于互联网企业日志分析场景。应用ELK组件搭建采集架构(图2:文本采集架构)通过Filebeat采集数据并发送到Logstash进行整合及过滤并保存到数据库。
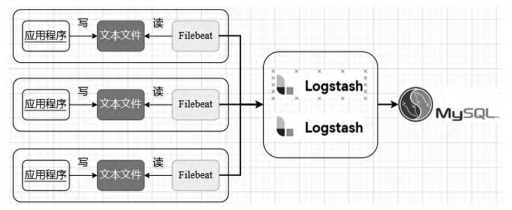
图 2 文本采集架构
Filebeat(日志采集器):用于转发和集中日志数据的轻量级传送程序。安装在数据端,监视指定的日志文件或数据,收集日志事件,并将它们转发到ElasticSearch或Logstash进行处理,且Filebeat使用背压敏感技术协议,用于应对大数据量处理。如果Logstash处理量过大时,通知Filebeat减慢传输速度。待拥堵得到解决后,自动恢复到原来的速度并继续传输数据。
Logstash(日志的收集,过滤和格式化):是服务器端数据处理管道,具有实时流水线功能的开源数据收集引擎。能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用Grok从非结构化数据中,解析出结构、匿名化或排除敏感字段,不受数据源、格式及结构上的差异,并提供了众多输出选项。Logstash使用了可插拔架构,共有二百多种插件。能够把不同的输入输出方式、筛选程序与输出选项混合搭配,精心安排,使它们在流水线上相互配合完成工作。现场应用中只需简单配置就可以运行采集方案。
(1)Filebeat配置(图3)

图3 Filebeat配置
主要配置项有“input_type”用于设置数据源类型文本类设置为log,“paths”设置采集文件路径,“output.logstash”用于设置Lostash服务接收端IP地址和端口。
(2)Logstash配置(图4):
配置输入(input)、过滤(filter)、输出(output)内容就可以从各种操作系统端(包括windowsxp等旧系统)采集所需数据,并通过grok插件编写表达式对数据进行过滤及整合、使用logstash-out-jdbc插件输出到指定数据库。

图 4 Logstash 配置
2 生产线设备数据采集
生产线数据采集结构模型,应该分为三级:现场设备、监控和监视。
2.1 现场设备层
有两个方案,可以根据现场实际进行混合使用:
(1)方案1如图5
生产线各类数据通过串口通信、现场总线、多主站通信、网口等方式汇总写入PLC寄存器,再通过以太网OPCDA/UA方式采集。
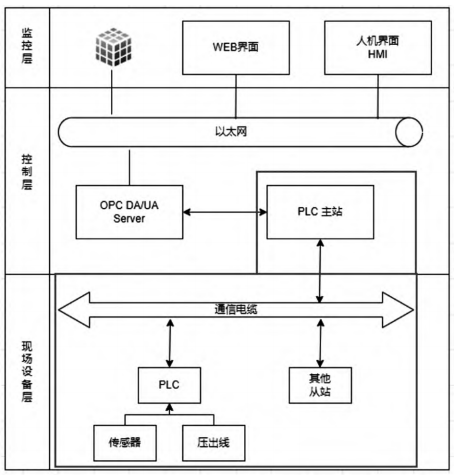
图 5 生产线 PLC 数据采集方案
现场设备层上,布设有多个感应器分别收集生产线上各方面信息,并传给作为采集点的PLC系统,然后再经由通信线路传给主站,主站PLC系统将获得的信息反馈给控制层MES或服务器,实现了对产品的工作情况进行现场监测。另一方面,由上层设备对所获取的信息加以整理和分析,确定异常情况,并做出相对响应的命令下传给PLC,最后再由PLC对下层设备做出相对对应的操作控制。
(2)方案2如图6
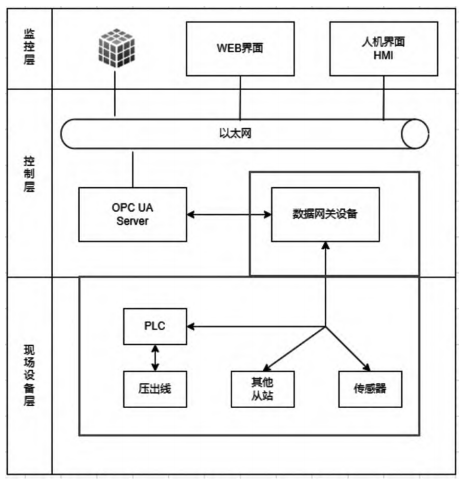
图 6 使用数据网关采集方案
生产线各类数据接入“工业网关设备”(如极智通)各类传感器无需写入PLC直接通过OPCUA接口采集数据,“工业网关设备”的各种通信连接:最主要的有线连接形式包括CAN、232接口/485、Ethernet等,232接口/485主要用于早期设备的管理和中低频率传输,而Ethernet技术对长距离、较大信息量的传感器数据也十分安全稳定有效,“工业网关设备”配置方案既实现了管理简单、多模式、对人机交互友好,而且既可使用本地网络、串口等方式实现设备管理,也可进行跨网段实现管理。
2.2 控制层
使用OPC UA进行采集及控制。OPC系统架构规范是一个WebService方法的不依靠操作系统的规范,根据该规范不同类型的操作系统与机器之间可以在各种计算机网络上,采用Client/Server方式实现通讯。OPC统一体系结构通过识别用户和服务端身分并主动抵御攻击,以保障双方安全的通讯。
OPC UA描述了一个服务器端所能提供的功能,特定的服务器端必须要求用户详细描述其能提供的业务。数据可以使用标准的由宿主程序确定的类型来表示。由服务器确定用户可以识别的数据模型,用户能够建立查询实时信息和历史数据的入口,同时可以透过报警和事件组件来告诉服务器重要的变化或正在发生的事情。OPC UA可以被映射到一种通信协议上并且数据可以以不同的形式进行编码来达到传输便捷和高效的目的。
表1 OPC server 商用 / 免费软件

OPC UA Server/Client可以采购商用软件(表1)或使用开源库进行二次开发。如JAVAMilo库就是Eclipse的物联网产品,是一种高性能的OPC UA栈,提供了一个客户端与服务器的API,用于对实时信息的存取、监视、报警、订阅信息、支持事件、历史数据浏览,以及信息建模。
3 异构数据源采集
ETL是实现异构数据采集的有效方法,在数据集成领域中ETL也具有其本身的若干特性,比如,异构数据源间的数据类型差异性很大,不但具有结构化数据,而且有大量半结构、无结构数据,数据在提取和加载的过程中需要实现远程传送;还涉及到对数据的编辑和删除。基于上述特点,基于KETTLE建立了ETL的过程模型,用于提供数据集成解决方案。
3.1 过程模型
ETL是数据抽取(Extract)、转换(Transform)和加载(Load)的英文简称,是对分散在各业务系统中的现有数据进行抽取、转换、清洗和加载的过程,使这些数据成为商业智能系统需要的有用数据。
KETTLE是构建数据集成解决方案的ETL工具,利用通过制定作业(Job)以及转换(Transform)实现对信息资源的抽取、转换和加载,KETTLE的ETL引擎是异构数据源融合和同时执行Job和Transform的技术核心,并能够运行在不同的操作系统上。图7是由KETTLE建立的ETL过程模型。
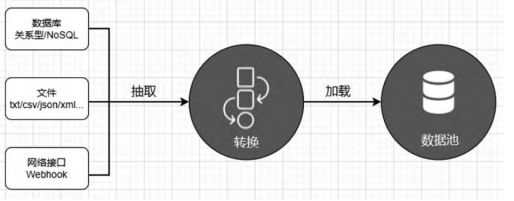
图7 过程模型
企业数据的保存方法多种多样,且存储位置不相同,关键是同时需要能够访问本地数据和远程数据源。通过配置与DB2、MySQL、MS Server等关系型数据库,Hadoop大数据数据库,MongoDB等非关系型数据库的连接信息以及获取半结构化、非结构化的文本文件、电子表格等文件的路径实现对数据源的访问。
3.2 概念模型
KETTLE实现数据集成主要由Job和Transform两大部分组成。ETL活动是一个四元组A=(ID,I,O,S),ID是活动标识符,I是输入模式的集合,O是输出模式的集合,S是一个或多个扩展的关系代数表达式,表示每个输出模式的语义。KETTLEETL的基本概念模式在图8中给出。
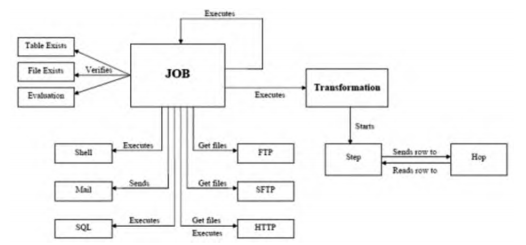
图 8 概念模型
(1)Transform(转换):一种对数据作业的容器,其作业内容是将数据任务由导入到产出的整个流程,可表现为比Job粒度要小一级的工作容器,首先将任务细分为Job,然后根据需要再把Job分割成一个或多个的Transform,但每次Transform都只能完成一个任务。
(2)Step(步骤):是转换的构建模块,也就是一个文件导入或是输出一个数据就是一个步骤。在PDI中包括官方提供的一百四十多种步骤。包括输入、输出、转换、应用、流程、连接、检验、加密、统计、脚本等。可以通过不同的排列及配置一系列步骤完成我们需要的数据集采工作。
(3)Hops(节点连接):是信息的通路,用来衔接二个步骤Step,使元数据由某个环节传送至另一环节。在如上图所示的转换中,它像似按次序进行中的,而实际并非如此。节点连接确定了贯通于流程内部的数据流,进程内部的先后顺序是非转化完成的先后顺序。在进行一次转化后,各个进程都有独立的线程启动,并不断的接收和传递数据。
(4)Jobs(工作):是指基于工作流模式的,协调数据源、执行工作流程以及相互依赖性的ETL活动。组织各种转换一起完成一个工作,一般我们会将一项重大的目标分解成若干个逻辑上分离的Job,如果这些Job全部成功,也就表示这个任务执行成功。
3.3 ETL关键技术
ETL以任务(Job和Transform)的方式定义数据抽取、转换和加载的过程,通过执行任务实现对数据的集成。从三个方面介绍ETL的关键技术。
3.3.1 多数据源抽取
(1)关系型数据库
关系型数据库存储的结构化数据类型能够很简单地转化为KETTLE数据流。KETTLE通过JDBC标准解决不同数据库系统之间数据类型上的差异性,通过JDBC-ODBC桥接支持开放式数据库连接(ODBC)接口。
(2)普通文件
Excel、CSV、等文本文件数据也可以用ETL抽取数据,而对于其中包含目录等信息数据的半结构化数据,在处理中,通过KETTLE将目录数据转换为结构化的数据表示,所转化的信息包括名称、目录的路径、大小、目录类型和列信息。转换后数据与操作关系型数据库类似。
3.3.2 数据库增量同步数据
(1)时间戳方式
在源表中添加timestamp类型字段,在系统中的每次增删(逻辑删除)或改查时,必须同步更新字段内容。在数据抽取时,获取timestamp字段与数据源timestamp进行比较来决定抽取那些数据,如图9。
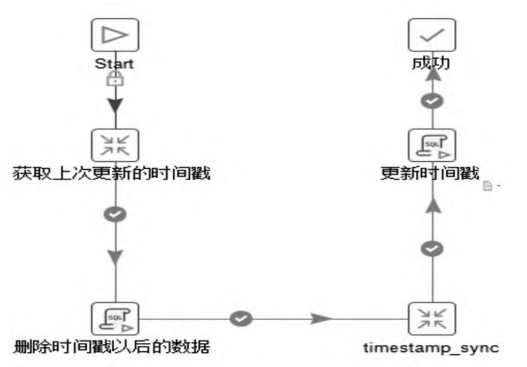
图 9 数据比较
(2)触发器方式
数据库中增加触发器,每当原表中数据发生变化时,写入临时表,抽取任务从临时表中抽取,临时表中抽取过的数据被标记或者删除。
(3)日志方式
在关系式数据库中,日志列表中记载着增删或修改事件的列表、描述符、日期和操作类别等信息,可以通过分析数据库的日志判断正在变化的数据。利用第三方工具可以将日志文档输出为可读的格式,在KETTLE得到了这些文档之后进行了相应作业和转换以进行增量数据收集。
3.3.3 应用实例
主要应用于不同系统数据库之间数据传输与过滤、整合,同时运行失败是可以发送邮件或者web hook发送信息给钉钉机器人。
本文以生产日报数据为例,说明了ETL的处理过程。
生产日报作为每日生产信息的汇总,需要包含产量、发货、品质、设备运行情况,为此需要对生产数据进行汇总计算处理,如计算设备运转率,同时需要从其他系统采集数据(如发货情况需要从出库系统获取)作业流程如图10所示。
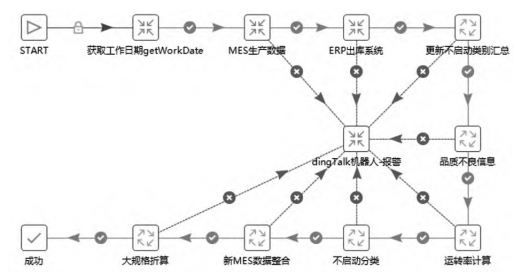
图10 生产日报数据
4 结束语
本文设计的面向生产现场的数据采集系统,实现开源软件与现场底层硬件、通讯技术的深度融合。将时下应用广泛的互联网软件技术ELK、KETTLE及OPC UA和PLC应用到本系统中,并结合实际需求,研究了一种高效可行的解决方案。本系统可广泛应用在数据采集及整合案例中(图11),能够适应企业现场复杂多变的管理要求,迅速的进行自动、精确、安全的数据提取、转化与加载,高效的将业务管理系统的重要数据转化成可管理性数据,有效解决了管理人员对生产数据信息的检索、统计分析、生产控制的需求。
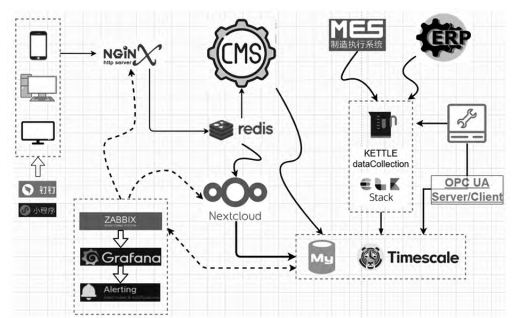
图11 数据采集整合
作者:杭州海潮橡胶有限公司 朴龙吉 胡鲁杰&中策橡胶集团有限公司 朴龙哲
相关新闻
版权声明
1、凡本网注明“来源:中国轻工业网” 的作品,版权均属于中国轻工业网,未经本网授权,任何单位及个人不得转载、摘编或以其它方式使用。已经本网授权使用作品的,应在授权范围内使用,并注明“来源:中国轻工业网”。违反上述声明者,本网将追究其相关法律责任。
2、凡本网注明 “来源:XXX(非中国轻工业网)” 的作品,均转载自其它媒体,转载目的在于信息之传播,并不代表本网赞同其观点和对其真实性负责。
3、如因作品内容、版权和其它问题需要同本网联系的,请于转载之日起30日内进行。
4、免责声明:本站信息及数据均为非营利用途,转载文章版权归信息来源网站或原作者所有。





